

Database File Maintenance Typically Involves
4
Dave Bourgeois and David T. Conservative
Learning Objectives
Upon successful completion of this chapter, you will be able to:
- describe the differences between information, information, and cognition;
- define the term database and place the steps to creating one;
- depict the part of a database management system;
- describe the characteristics of a data warehouse; and
- define data mining and describe its role in an organisation.
Please note, there is an updated edition of this volume bachelor at https://opentextbook.site. If you lot are not required to use this edition for a class, y'all may want to check it out.
Introduction
Y'all accept already been introduced to the outset two components of information systems: hardware and software. Nonetheless, those two components by themselves practise not make a computer useful. Imagine if y'all turned on a computer, started the word processor, but could non save a certificate. Imagine if y'all opened a music player merely there was no music to play. Imagine opening a spider web browser but in that location were no web pages. Without data, hardware and software are not very useful! Data is the tertiary component of an information organization.
Data, Data, and Knowledge
Data are the raw bits and pieces of information with no context. If I told yous, "fifteen, 23, 14, 85," yous would non have learned anything. But I would have given you data.
Information can exist quantitative or qualitative. Quantitative data is numeric, the consequence of a measurement, count, or some other mathematical calculation. Qualitative data is descriptive."Ruby Cerise," t he color of a 2013 Ford Focus, is a n case of qualitative data. A number tin be qualitative likewise: if I tell y'all my favorite number is 5, that is qualitative data because it is descriptive, not the result of a measurement or mathematical calculation.
 By itself, data is not that useful. To be useful, information technology needs to be given context. Returning to the example above, if I told y'all that "fifteen, 23, fourteen, and 85″ are the numbers of students that had registered for upcoming classes, that would be data . By calculation the context – that the numbers represent the count of students registering for specific classes – I have converted data into data.
By itself, data is not that useful. To be useful, information technology needs to be given context. Returning to the example above, if I told y'all that "fifteen, 23, fourteen, and 85″ are the numbers of students that had registered for upcoming classes, that would be data . By calculation the context – that the numbers represent the count of students registering for specific classes – I have converted data into data.
Once nosotros take put our data into context, aggregated and analyzed it, we can use it to make decisions for our organization. We can say that this consumption of information produces knowledge. This knowledge can be used to make decisions, prepare policies, and fifty-fifty spark innovation.
The final step up the information ladder is the stride from cognition (knowing a lot about a topic) towisdom. We tin can say that someone has wisdom when they tin can combine their knowledge and experience to produce a deeper understanding of a topic. It frequently takes many years to develop wisdom on a particular topic, and requires patience.
Examples of Data
Almost all software programs require data to do anything useful. For example, if you lot are editing a document in a give-and-take processor such as Microsoft Discussion, the document you lot are working on is the data. The discussion-processing software can dispense the data: create a new document, indistinguishable a document, or change a document. Some other examples of data are: an MP3 music file, a video file, a spreadsheet, a web page, and an e-book. In some cases, such as with an eastward-book, you may only have the power to read the information.
Databases
The goal of many data systems is to transform data into information in order to generate knowledge that tin can be used for determination making. In order to do this, the system must be able to accept data, put the data into context, and provide tools for assemblage and assay. A database is designed for merely such a purpose.
A database is an organized collection of related information. It is anorganized collection, because in a database, all data is described and associated with other data. All information in a database should be related also; separate databases should be created to manage unrelated information. For example, a database that contains information about students should non also hold data nigh company stock prices. Databases are not always digital – a filing cabinet, for example, might be considered a form of database. For the purposes of this text, we will only consider digital databases.
Relational Databases
Databases can be organized in many different ways, and thus accept many forms. The almost popular form of database today is the relational database. Popular examples of relational databases are Microsoft Access, MySQL, and Oracle. A relational database is ane in which data is organized into i or more tables. Each table has a set up of fields, which define the nature of the information stored in the table. A tape is 1 instance of a gear up of fields in a table. To visualize this, call up of the records as the rows of the table and the fields as the columns of the table. In the instance below, we have a tabular array of student information, with each row representing a educatee and each column representing one piece of information about the pupil.
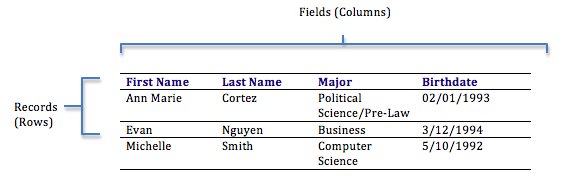
In a relational database, all the tables are related by one or more fields, so that it is possible to connect all the tables in the database through the field(s) they have in mutual. For each table, one of the fields is identified equally a primary key. This central is the unique identifier for each record in the tabular array. To assistance you understand these terms further, permit's walk through the process of designing a database.
Designing a Database
Suppose a university wants to create an data system to rail participation in student clubs. Later on interviewing several people, the pattern team learns that the goal of implementing the organisation is to requite ameliorate insight into how the university funds clubs. This volition be achieved past tracking how many members each club has and how active the clubs are. From this, the team decides that the system must proceed track of the clubs, their members, and their events. Using this data, the design team determines that the following tables demand to be created:
- Clubs: this volition rail the guild name, the lodge president, and a short description of the guild.
- Students: student name, e-post, and year of nascency.
- Memberships: this table will correlate students with clubs, allowing us to accept whatsoever given student join multiple clubs.
- Events: this table will track when the clubs meet and how many students showed upwards.
Now that the design team has determined which tables to create, they need to define the specific information that each table volition concord. This requires identifying the fields that will exist in each table. For example, Club Proper noun would be one of the fields in the Clubs table. First Name and Last Name would be fields in the Students table. Finally, since this will exist a relational database, every table should take a field in mutual with at to the lowest degree one other table (in other words: they should have a human relationship with each other).
In order to properly create this relationship, a primary key must be selected for each table. This cardinal is a unique identifier for each record in the table. For example, in the Students tabular array, information technology might exist possible to use students' last name as a way to uniquely identify them. However, information technology is more than likely that some students will share a last name (like Rodriguez, Smith, or Lee), and so a different field should exist selected. A pupil'south eastward-mail address might be a good pick for a principal key, since eastward-mail addresses are unique. However, a primary central cannot change, and then this would mean that if students changed their due east-mail address we would accept to remove them from the database and and then re-insert them – not an attractive proffer. Our solution is to create a value for each pupil — a user ID — that will deed as a principal key. We will also practise this for each of the student clubs. This solution is quite mutual and is the reason you lot have so many user IDs!
You tin can see the last database design in the effigy beneath:
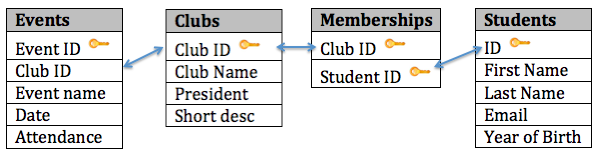
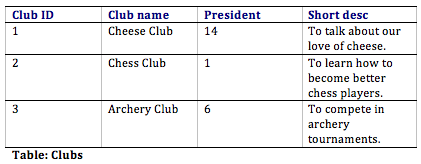
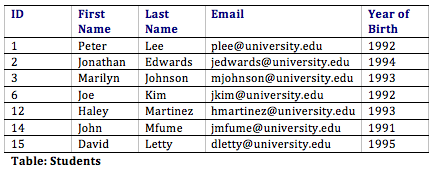
With this pattern, not simply do we have a way to organize all of the information we demand to meet the requirements, but we take as well successfully related all the tables together. Here's what the database tables might await like with some sample data. Note that the Memberships table has the sole purpose of allowing u.s.a. to relate multiple students to multiple clubs.
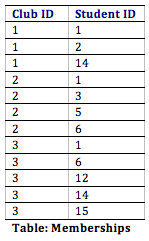
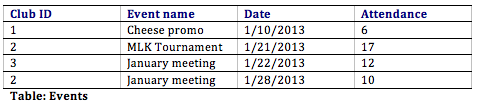
Normalization
When designing a database, ane important concept to sympathize is normalization. In unproblematic terms, to normalize a database means to design it in a way that: 1) reduces duplication of data between tables and 2) gives the table as much flexibility as possible.
In the Student Clubs database pattern, the design team worked to reach these objectives. For example, to track memberships, a simple solution might accept been to create a Members field in the Clubs tabular array and so simply list the names of all of the members there. However, this design would mean that if a student joined two clubs, then his or her information would have to be entered a second fourth dimension. Instead, the designers solved this problem by using two tables: Students and Memberships.
In this blueprint, when a student joins their kickoff club, we first must add the pupil to the Students table, where their beginning name, last name, e-mail service accost, and nascency year are entered. This add-on to the Students tabular array volition generate a educatee ID. At present we will add a new entry to denote that the student is a member of a specific club. This is accomplished by adding a record with the educatee ID and the guild ID in the Memberships table. If this student joins a second club, nosotros practice not have to indistinguishable the entry of the student's proper noun, eastward-post, and birth year; instead, nosotros just need to make some other entry in the Memberships table of the 2d club's ID and the educatee's ID.
The design of the Student Clubs database also makes it simple to change the design without major modifications to the existing structure. For example, if the blueprint team were asked to add functionality to the system to track faculty advisors to the clubs, we could hands achieve this past adding a Faculty Advisors table (similar to the Students table) then calculation a new field to the Clubs table to agree the Faculty Advisor ID.
Information Types
When defining the fields in a database tabular array, we must requite each field a data type. For example, the field Birth Year is a year, so it will be a number, while Beginning Proper noun will exist text. Nearly mod databases allow for several dissimilar information types to be stored. Some of the more common data types are listed here:
- Text: for storing non-numeric data that is brief, mostly under 256 characters. The database designer can identify the maximum length of the text.
- Number: for storing numbers. There are usually a few different number types that can be selected, depending on how large the largest number volition be.
- Yes/No: a special form of the number data type that is (ordinarily) 1 byte long, with a 0 for "No" or "False" and a 1 for "Yes" or "True".
- Date/Time: a special form of the number data blazon that tin exist interpreted every bit a number or a fourth dimension.
- Currency: a special course of the number data type that formats all values with a currency indicator and two decimal places.
- Paragraph Text: this information blazon allows for text longer than 256 characters.
- Object: this data blazon allows for the storage of data that cannot be entered via keyboard, such equally an image or a music file.
In that location are 2 important reasons that nosotros must properly define the information blazon of a field. First, a data type tells the database what functions can be performed with the data. For example, if we wish to perform mathematical functions with one of the fields, we must be sure to tell the database that the field is a number information type. And then if we have, say, a field storing birth year, we can subtract the number stored in that field from the current year to get age.
The second of import reason to define information type is so that the proper amount of storage space is allocated for our data. For example, if the Outset Name field is divers as a text(50) data blazon, this means fifty characters are allocated for each first name nosotros want to store. However, even if the first proper name is only five characters long, fifty characters (bytes) volition be allocated. While this may not seem like a big deal, if our tabular array ends up holding 50,000 names, we are allocating fifty * 50,000 = two,500,000 bytes for storage of these values. It may be prudent to reduce the size of the field so nosotros do not waste storage space.
Sidebar: The Divergence between a Database and a Spreadsheet
Many times, when introducing the concept of databases to students, they speedily determine that a database is pretty much the aforementioned as a spreadsheet. Later on all, a spreadsheet stores information in an organized fashion, using rows and columns, and looks very similar to a database tabular array. This misunderstanding extends beyond the classroom: spreadsheets are used as a substitute for databases in all types of situations every twenty-four hour period, all over the world.
To be off-white, for simple uses, a spreadsheet tin substitute for a database quite well. If a simple listing of rows and columns (a single table) is all that is needed, then creating a database is probably overkill. In our Pupil Clubs example, if we only needed to runway a list of clubs, the number of members, and the contact information for the president, we could become away with a unmarried spreadsheet. Even so, the need to include a list of events and the names of members would be problematic if tracked with a spreadsheet.
When several types of data must be mixed together, or when the relationships between these types of data are complex, so a spreadsheet is not the best solution. A database allows information from several entities (such as students, clubs, memberships, and events) to all be related together into one whole. While a spreadsheet does allow y'all to ascertain what kinds of values can exist entered into its cells, a database provides more intuitive and powerful means to define the types of data that go into each field, reducing possible errors and allowing for easier analysis.
Though not skilful for replacing databases, spreadsheets can be ideal tools for analyzing the data stored in a database. A spreadsheet package can be connected to a specific tabular array or query in a database and used to create charts or perform analysis on that data.
Structured Query Language
Once you have a database designed and loaded with data, how will you do something useful with it? The primary style to work with a relational database is to apply Structured Query Language, SQL (pronounced "sequel," or simply stated as S-Q-L). Almost all applications that piece of work with databases (such as database management systems, discussed beneath) make use of SQL every bit a way to analyze and dispense relational data. Equally its name implies, SQL is a linguistic communication that can exist used to work with a relational database. From a unproblematic request for data to a complex update operation, SQL is a mainstay of programmers and database administrators. To give you a gustation of what SQL might wait similar, here are a couple of examples using our Student Clubs database.
- The post-obit query will remember a listing of the first and last names of the club presidents:
SELECT "First Proper name", "Last Proper noun" FROM "Students" WHERE "Students.ID" = "Clubs.President"
- The following query will create a list of the number of students in each club, listing the order proper noun and then the number of members:
SELECT "Clubs.Club Name", COUNT("Memberships.Student ID") FROM "Clubs" LEFT Join "Memberships" ON "Clubs.Club ID" = "Memberships.Lodge ID" An in-depth description of how SQL works is across the scope of this introductory text, but these examples should give y'all an idea of the power of using SQL to manipulate relational data. Many database packages, such as Microsoft Access, allow you to visually create the query yous want to construct and then generate the SQL query for you.
Other Types of Databases
The relational database model is the about used database model today. However, many other database models exist that provide unlike strengths than the relational model. The hierarchical database model, popular in the 1960s and 1970s, connected information together in a hierarchy, allowing for a parent/child relationship betwixt data. The document-centric model allowed for a more than unstructured data storage past placing data into "documents" that could then be manipulated.
Perhaps the most interesting new development is the concept of NoSQL (from the phrase "not just SQL"). NoSQL arose from the demand to solve the problem of large-scale databases spread over several servers or even across the world. For a relational database to work properly, it is important that just one person exist able to manipulate a piece of data at a time, a concept known equally record-locking. But with today's large-scale databases (retrieve Google and Amazon), this is just non possible. A NoSQL database tin work with information in a looser manner, assuasive for a more unstructured environs, communicating changes to the data over time to all the servers that are part of the database.
Database Management Systems
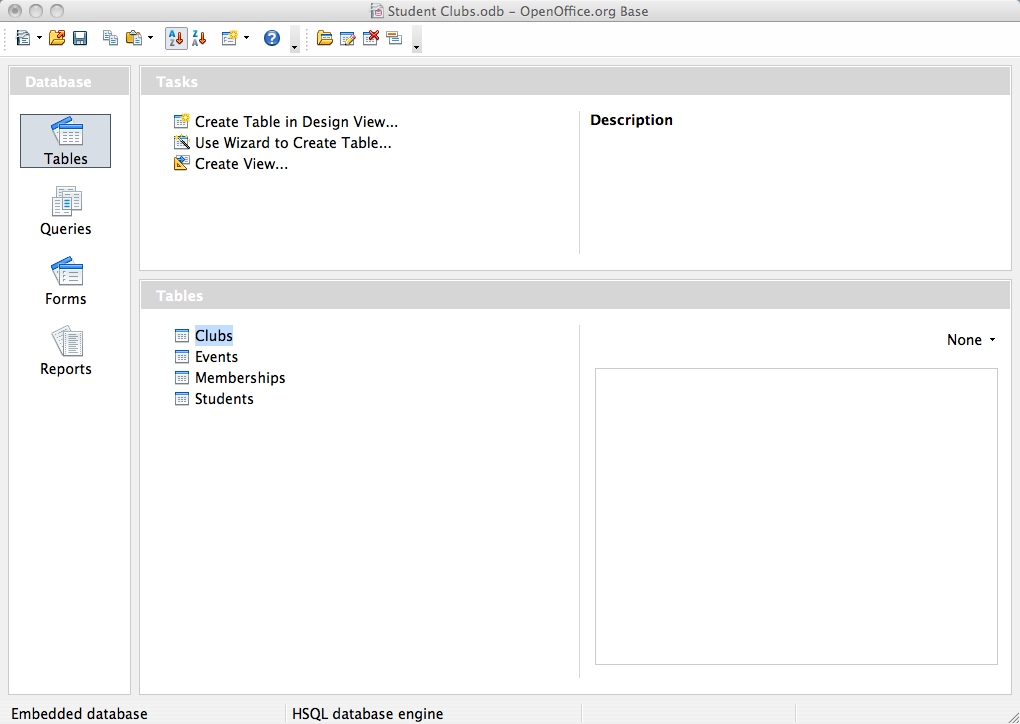
To the computer, a database looks like one or more files. In gild for the data in the database to exist read, changed, added, or removed, a software plan must access it. Many software applications take this ability: iTunes can read its database to requite you a listing of its songs (and play the songs); your mobile-phone software can interact with your list of contacts. But what near applications to create or manage a database? What software can y'all apply to create a database, alter a database'southward structure, or only do analysis? That is the purpose of a category of software applications called database management systems (DBMS).
DBMS packages more often than not provide an interface to view and change the blueprint of the database, create queries, and develop reports. Virtually of these packages are designed to piece of work with a specific type of database, but generally are compatible with a wide range of databases.
For instance, Apache OpenOffice.org Base (come across screen shot) can be used to create, change, and clarify databases in open-database (ODB) format. Microsoft'south Access DBMS is used to work with databases in its ain Microsoft Admission Database format. Both Access and Base have the ability to read and write to other database formats also.
Microsoft Access and Open Office Base are examples of personal database-management systems. These systems are primarily used to develop and analyze single-user databases. These databases are not meant to be shared beyond a network or the Cyberspace, merely are instead installed on a particular device and work with a single user at a time.
Enterprise Databases
A database that can only be used past a single user at a fourth dimension is not going to meet the needs of most organizations. Equally computers take go networked and are now joined worldwide via the Internet, a class of database has emerged that can be accessed by two, ten, or even a million people. These databases are sometimes installed on a single computer to be accessed by a group of people at a single location. Other times, they are installed over several servers worldwide, meant to be accessed past millions. These relational enterprise database packages are built and supported by companies such equally Oracle, Microsoft, and IBM. The open-source MySQL is also an enterprise database.
Equally stated earlier, the relational database model does not scale well. The term calibration here refers to a database getting larger and larger, existence distributed on a larger number of computers connected via a network. Some companies are looking to provide large-scale database solutions past moving away from the relational model to other, more flexible models. For case, Google now offers the App Engine Datastore, which is based on NoSQL. Developers can use the App Engine Datastore to develop applications that admission data from anywhere in the earth. Amazon.com offers several database services for enterprise use, including Amazon RDS, which is a relational database service, and Amazon DynamoDB, a NoSQL enterprise solution.
Big Information
A new buzzword that has been capturing the attention of businesses lately is big data. The term refers to such massively large data sets that conventional database tools exercise not have the processing power to analyze them. For instance, Walmart must procedure over one million customer transactions every hour. Storing and analyzing that much data is across the power of traditional database-management tools. Understanding the best tools and techniques to manage and analyze these large data sets is a problem that governments and businesses alike are trying to solve.
Sidebar: What Is Metadata?
The term metadata can be understood as "information most information." For example, when looking at one of the values of Year of Birth in the Students tabular array, the information itself may be "1992". The metadata almost that value would be the field proper name Yr of Birth, the time it was last updated, and the information type (integer). Some other example of metadata could be for an MP3 music file, similar the one shown in the image below; information such equally the length of the song, the artist, the album, the file size, and fifty-fifty the album cover fine art, are classified as metadata. When a database is being designed, a "data dictionary" is created to concur the metadata, defining the fields and structure of the database.
-
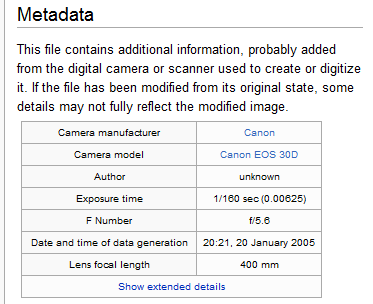
Metadata about a camera image (Public Domain)
Data Warehouse
As organizations accept begun to use databases every bit the centerpiece of their operations, the need to fully understand and leverage the information they are collecting has go more and more apparent. However, straight analyzing the information that is needed for day-to-day operations is not a skilful thought; we do non want to revenue enhancement the operations of the visitor more than we need to. Further, organizations also want to analyze data in a historical sense: How does the data we have today compare with the aforementioned set of data this fourth dimension last month, or last year? From these needs arose the concept of the information warehouse.
The concept of the data warehouse is elementary: extract data from ane or more than of the organisation's databases and load it into the information warehouse (which is itself another database) for storage and analysis. Nevertheless, the execution of this concept is not that simple. A information warehouse should be designed then that it meets the following criteria:
- It uses non-operational data. This means that the data warehouse is using a copy of data from the active databases that the visitor uses in its day-to-day operations, and so the information warehouse must pull information from the existing databases on a regular, scheduled basis.
- The information is time-variant. This means that whenever data is loaded into the information warehouse, it receives a time stamp, which allows for comparisons between different time periods.
- The data is standardized. Because the data in a information warehouse ordinarily comes from several dissimilar sources, it is possible that the data does not use the same definitions or units. For example, our Events table in our Student Clubs database lists the issue dates using the mm/dd/yyyy format (due east.g., 01/10/2013). A table in some other database might use the format yy/mm/dd (eastward.chiliad., 13/01/10) for dates. In order for the data warehouse to match up dates, a standard appointment format would have to be agreed upon and all data loaded into the data warehouse would have to be converted to utilize this standard format. This procedure is called extraction-transformation-load (ETL).
There are ii primary schools of thought when designing a data warehouse: lesser-up and peak-down. The lesser-up arroyo starts by creating small data warehouses, called data marts, to solve specific business bug. As these data marts are created, they tin be combined into a larger data warehouse. The superlative-downwardly approach suggests that we should starting time past creating an enterprise-wide information warehouse and and then, equally specific business needs are identified, create smaller data marts from the data warehouse.
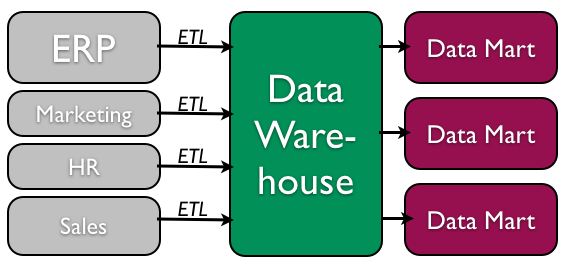
Benefits of Data Warehouses
Organizations notice information warehouses quite benign for a number of reasons:
- The process of developing a data warehouse forces an organization to better understand the information that it is currently collecting and, equally important, what data is not being nerveless.
- A data warehouse provides a centralized view of all information existence collected beyond the enterprise and provides a means for determining data that is inconsistent.
- Once all data is identified equally consistent, an organisation can generate one version of the truth. This is important when the company wants to report consistent statistics about itself, such equally acquirement or number of employees.
- Past having a data warehouse, snapshots of data can be taken over fourth dimension. This creates a historical record of data, which allows for an analysis of trends.
- A data warehouse provides tools to combine data, which tin provide new data and analysis.
Information Mining
Data mining is the process of analyzing information to detect previously unknown trends, patterns, and associations in order to make decisions. Mostly, information mining is accomplished through automated ways confronting extremely large data sets, such every bit a data warehouse. Some examples of data mining include:
- An assay of sales from a large grocery chain might determine that milk is purchased more frequently the mean solar day later on it rains in cities with a population of less than 50,000.
- A banking concern may find that loan applicants whose bank accounts testify particular deposit and withdrawal patterns are not adept credit risks.
- A baseball team may discover that collegiate baseball players with specific statistics in hitting, pitching, and fielding make for more successful major league players.
In some cases, a data-mining project is begun with a hypothetical outcome in heed. For instance, a grocery chain may already have some idea that ownership patterns change afterwards it rains and desire to get a deeper agreement of exactly what is happening. In other cases, in that location are no presuppositions and a information-mining programme is run confronting large data sets in guild to find patterns and associations.
Privacy Concerns
The increasing ability of data mining has caused concerns for many, especially in the area of privacy. In today's digital globe, it is becoming easier than ever to take data from disparate sources and combine them to do new forms of analysis. In fact, a whole manufacture has sprung upward around this technology: data brokers. These firms combine publicly accessible information with information obtained from the government and other sources to create vast warehouses of information nearly people and companies that they can and then sell. This subject volition be covered in much more detail in chapter 12 – the affiliate on the ethical concerns of information systems.
Business Intelligence and Business Analytics
With tools such equally data warehousing and data mining at their disposal, businesses are learning how to use information to their advantage. The term business intelligence is used to depict the process that organizations use to take data they are collecting and analyze it in the hopes of obtaining a competitive advantage. Besides using information from their internal databases, firms oftentimes purchase information from data brokers to get a big-picture understanding of their industries. Business analytics is the term used to depict the apply of internal company information to amend business processes and practices.
Cognition Direction
We cease the chapter with a discussion on the concept of knowledge management (KM). All companies accumulate knowledge over the course of their existence. Some of this knowledge is written down or saved, only non in an organized fashion. Much of this noesis is not written down; instead, it is stored inside the heads of its employees. Knowledge management is the process of formalizing the capture, indexing, and storing of the company'due south knowledge in social club to benefit from the experiences and insights that the visitor has captured during its being.
Summary
In this affiliate, we learned about the office that data and databases play in the context of information systems. Data is made up of minor facts and information without context. If you lot give data context, then you lot have information. Knowledge is gained when information is consumed and used for determination making. A database is an organized collection of related information. Relational databases are the almost widely used type of database, where data is structured into tables and all tables must exist related to each other through unique identifiers. A database management system (DBMS) is a software application that is used to create and manage databases, and can take the form of a personal DBMS, used by i person, or an enterprise DBMS that can be used past multiple users. A information warehouse is a special form of database that takes data from other databases in an enterprise and organizes it for analysis. Data mining is the process of looking for patterns and relationships in large data sets. Many businesses employ databases, data warehouses, and information-mining techniques in order to produce business intelligence and gain a competitive advantage.
Study Questions
- What is the divergence betwixt data, information, and noesis?
- Explain in your ain words how the data component relates to the hardware and software components of information systems.
- What is the difference between quantitative data and qualitative data? In what situations could the number 42 be considered qualitative data?
- What are the characteristics of a relational database?
- When would using a personal DBMS make sense?
- What is the difference between a spreadsheet and a database? Listing three differences between them.
- Describe what the term normalization means.
- Why is it of import to define the data type of a field when designing a relational database?
- Name a database you interact with frequently. What would some of the field names be?
- What is metadata?
- Name three advantages of using a data warehouse.
- What is data mining?
Exercises
- Review the blueprint of the Pupil Clubs database earlier in this affiliate. Reviewing the lists of information types given, what data types would you assign to each of the fields in each of the tables. What lengths would you assign to the text fields?
- Download Apache OpenOffice.org and utilize the database tool to open up the "Student Clubs.odb" file bachelor here. Take some time to larn how to modify the database structure and and so see if you tin can add the required items to support the tracking of kinesthesia advisors, equally described at the end of the Normalization department in the chapter. Here is a link to the Getting Started documentation.
- Using Microsoft Access, download the database file of comprehensive baseball statistics from the website SeanLahman.com. (If you don't have Microsoft Admission, you tin download an abridged version of the file here that is uniform with Apache Open Office). Review the construction of the tables included in the database. Come with three different information-mining experiments you would similar to try, and explicate which fields in which tables would have to be analyzed.
- Practise some original inquiry and find two examples of data mining. Summarize each case and and so write about what the ii examples accept in common.
- Conduct some independent research on the process of business organization intelligence. Using at least two scholarly or practitioner sources, write a two-page paper giving examples of how concern intelligence is beingness used.
- Conduct some independent research on the latest technologies being used for knowledge management. Using at to the lowest degree two scholarly or practitioner sources, write a two-folio paper giving examples of software applications or new technologies being used in this field.

Database File Maintenance Typically Involves,
Source: https://pressbooks.pub/bus206/chapter/chapter-4-data-and-databases/
Posted by: tyernage1964.blogspot.com
0 Response to "Database File Maintenance Typically Involves"
Post a Comment